Retrieval augmented generation (RAG)
Panoramica
La Retrieval augmented generation (RAG) è una tecnica che migliora gli LLM integrandoli con fonti di conoscenza esterne. RAG affronta una limitazione significativa dei modelli: dipendono da un dataset di addestramento statici, che possono risultare obsoleti o incompleti. Quando viene presentata una query, i sistemi RAG cercano prima una base di conoscenza per dati rilevanti. Queste informazioni recuperate vengono poi incorporate nel prompt del modello. Il modello utilizza questo contesto per generare una risposta alla query. Combinando gli LLM con un recupero di informazioni dinamico e mirato, RAG è un metodo potente per creare sistemi di intelligenza artificiale più precisi e affidabili.
Concetti Chiave
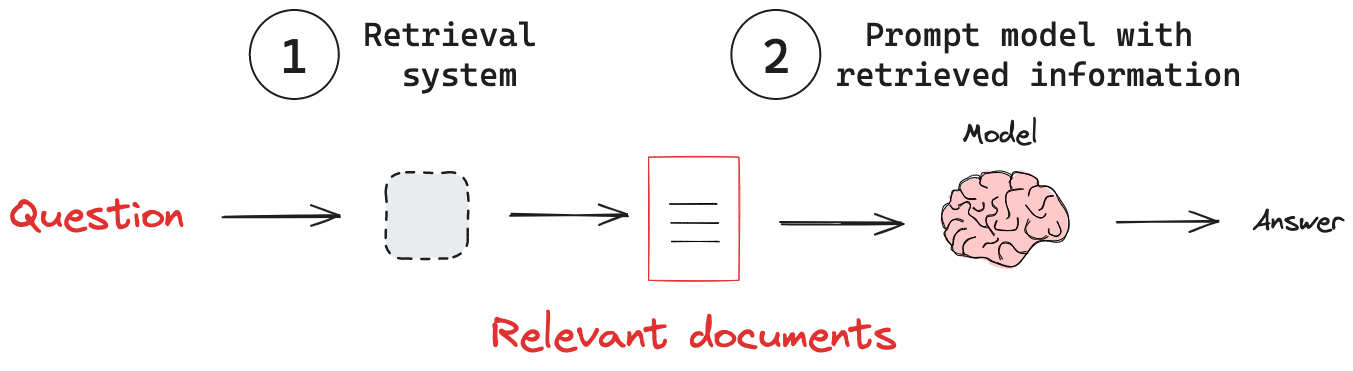
- Retrieval System: Estrae informazioni rilevanti da una base di conoscenza.
- Aggiunta di "External Knowledge": Fornisce le informazioni recuperate a un modello.
Retrieval System
I modelli hanno una conoscenza interna che è spesso statica o aggiornata raramente a causa dell'alto costo dell'addestramento. Questo limita la loro capacità di rispondere a domande su eventi attuali o di fornire conoscenze specifiche di dominio. Per affrontare questo problema, vengono utilizzate varie tecniche di iniezione di conoscenza come il fine-tuning o il pre-addestramento continuo. Entrambe sono costose. L'uso di un sistema di recupero offre diversi vantaggi:
- Informazioni Aggiornate: RAG può accedere e utilizzare i dati più recenti, mantenendo le risposte aggiornate.
- Esperienza Specifica di Dominio: con basi di conoscenza specifiche di dominio, RAG può fornire risposte in domini specifici.
- Riduzione delle Allucinazioni: basare le risposte su fatti recuperati aiuta a minimizzare informazioni false o inventate.
- Integrazione della Conoscenza Economica: RAG offre un'alternativa più efficiente rispetto al costoso fine-tuning del modello.
Consulta la nostra guida concettuale sul Retrieval.
Aggiunta di "External Knowledge"
Con un sistema di recupero in atto, dobbiamo passare la conoscenza da questo sistema al modello. Una pipeline RAG tipicamente segue questi passaggi:
- Riceve una query di input.
- Utilizza il sistema di recupero per cercare informazioni rilevanti basate sulla query.
- Incorpora le informazioni recuperate nel prompt inviato al LLM.
- Genera una risposta che sfrutta il contesto recuperato.
Ad esempio, ecco un semplice workflow RAG che passa informazioni da un Retrieval a un modello di chat:
import { LanguageModelV1 } from "ai";
import { createOpenAI } from "@ai-sdk/openai";
const openai = createOpenAI({
apiKey: process.env['OPENAI_API_KEY'], // This is the default and can be omitted
});
const model = openai("")
// Define a system prompt that tells the model how to use the retrieved context
const systemPrompt = `You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Context: {context}:`;
// Define a question
const question =
"What are the main components of an LLM-powered autonomous agent system?";
async function main() {
const stream = await streamText({
model: 'gpt-4o',
messages: [
{ role: 'system', content: systemPrompt },
{ role: 'user', content: question }
],
temperature: 1
})
// Generate a response
for await (const chunk of stream) {
process.stdout.write(chunk.choices[0]?.delta?.content || '');
}
}
main();